Tutorial - Managing Apache Storm with Roboconf and Docker - 2/5
This second part is a quick introduction to Apache Storm and how to deploy it as Docker containers.
Storm is an open source project, hosted by the Apache Foundation.
It focuses on distributed and real-time computation. It is generally associated with the « Big Data » trend,
since it can handle very large sets of data.
Two main things distinguish Storm from Hadoop.
-
Hadoop works in batch mode. Storm uses a stream flow, potentially forever. It means a Hadoop program will always terminate, unlike Storm. This has a major impact on the way we model processing. Hadoop uses « map-reduce » algorithms while Storm uses « topologies » that describe flow processing.
-
The second difference is a consequence of the previous mention.
Hadoop being a batch tool, it takes the time necessary to complete its processing. Storm gives the priority to the real-time aspect, which means the computation may loose in precision to respect the real-time constraint.
A common use-case of Storm involves the real-time analysis of tweets.
A Storm topology gathers tweets about a given trend and then associate to all of them a perception of the trend
(positive feedback, negative feedback, neutral). Over time, the topology allows to measure the impact of the trend
among Twitter users.
Obviously, there are many other use cases mentioned on Apache Storm’s web site.
Architecture
Storm is made up of 3 blocks:
- A master node, called Nimbus.
- Slave nodes, that perform computation. They are called workers or supervisor nodes.
- A block to manage the cluster, generally Zoo Keeper.
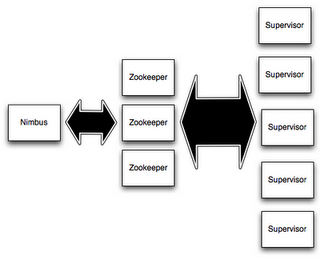
There exist a web interface to manage the cluster, as well as command-line client, to submit and manage topologies.
Storm Topologies
A Storm topology defines a graph of processing units. Data tuples are exchanged between these units (called spouts and bolts). Spouts are data sources (they produce data tuples). Bolts perform operations on these tuples, such as transformations.
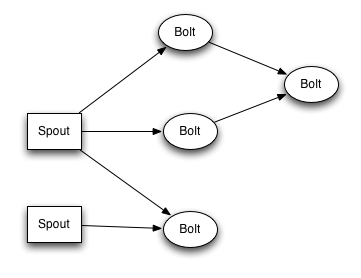
Storm topologies are packaged as JAR files (although other languages are supported). Once packaged, a topology can be submitted to the Nimbus, that will dispatch the processing units over the worker nodes.
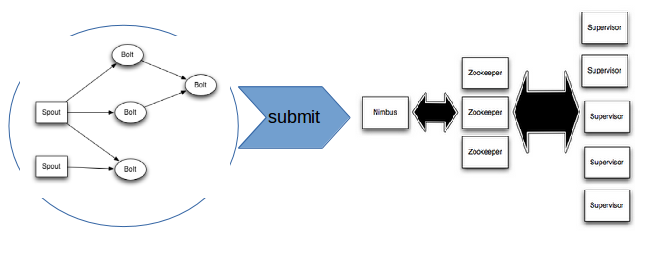
Storm allows to redistribute a topology when the cluster is modified. It can also reset lost processing when a node crashes. Please, refer to this page for more details.
Manual Deployment with Docker
First, it is necessary to understand how to deploy a Storm topology by hand with Docker.
Let’s get started with Zoo Keeper.
docker run -d --restart always --name zookeeper zookeeper:3.3
Let’s manage the Nimbus.
docker run -d --restart always --name nimbus --link zookeeper:zookeeper storm:1.1 storm nimbus
We can now create worker nodes…
docker run -d --restart always --name supervisor1 --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
docker run -d --restart always --name supervisor2 --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
# ...
docker run -d --restart always --name supervisorN --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
… followed by the web console.
# Available at http://localhost:9090/index.html
docker run -d -p 9090:8080 --restart always --name ui --link nimbus:nimbus storm:1.1 storm ui
Notice the various relations between these containers.
You will rebuild them in the Roboconf graph.
The last part implies deploying a topology to test it for real.
Among the Storm examples, which are all grouped together, we extracted a simple one that has the great
advantage of being light. It is shared here as a source project
to compile with Maven. This topology generates random words (data source) and computes their length (processing).
# The resulting JAR will be under the "target" directory
mvn clean package
You can now manage this topology by creating ephemeral Docker containers.
# Go into the "target" direcrory
cd target/
# Submit
docker run --link nimbus:nimbus -it --rm -v \
$(pwd)/storm-starter-word-count-1.1.0.jar:/topology.jar \
storm:1.1 storm jar /topology.jar org.apache.storm.starter.WordCountTopology <topology-name>
# Redistribute over the cluster
docker run --link nimbus:nimbus -it --rm storm:1.1 storm rebalance <topology-name>
# Delete
docker run --link nimbus:nimbus -it --rm storm:1.1 storm kill <topology-name>
Watch what happens in Storm’s web console.
Be careful, redistributing the topology over the cluster may take some time (tens of seconds).
Now that you are confident with Storm, let’s try to package it for Roboconf.