Tutoriel - Gestion de Apache Storm avec Docker - 2/5
Cette deuxième partie vous présente rapidement Apache Storm et vous propose de le déployer, dans un premier temps, manuellement, sous la forme de conteneurs Docker.
Storm est un projet Apache, open source donc, dédié au calcul distribué et à l’analyse temps réel.
Il est généralement associé au terme de « Big Data », dans la mesure où il est en capacité de gérer
de grands volumes de données.
Deux principaux éléments distinguent Storm de Hadoop.
-
Hadoop fonctionne en mode batch. Storm fonctionne sur un flux continu, potentiellement permanent. Cela signifie qu’un traitement Hadoop a forcément une fin, contrairement à un traitement Storm. Cela a un impact sur le modèle de traitement. Si Haddop parle d’algorithme « map-reduce », Storm utilise quant à lui des « topologies » qui décrivent les flux de traitement.
-
Le deuxième différenciateur est une conséquence de l’élément précédent.
Hadoop fonctionne en batch, ce qui signifie qu’il prend le temps nécessaire pour compléter son traitement. A l’inverse, Storm privilégie le temps réel, ce qui peut se faire au détriment de la précision des calculs.
Un exemple souvent mis en avant par Storm, concerne l’analyse temps réel de tweets.
On connecte une topologie pour qu’elle récupère un fil de tweets, et qu’elle associe à chacun d’entre eux
un sentiment (positif, neutre, négatif). Au fil des calculs, cela permet d’estimer l’impact d’un sujet auprès
des utilisateurs de Twitter.
Il existe bien entendu de nombreux autres exemples sur le site de Apache Storm.
Architecture
Storm est constitué de 3 éléments principaux :
- Un nœud maître, appelé Nimbus.
- Des nœuds esclaves, en charge des calculs. On les appelle des workers ou supervisor nodes.
- Une brique pour gérer le cluster, généralement Zoo Keeper.
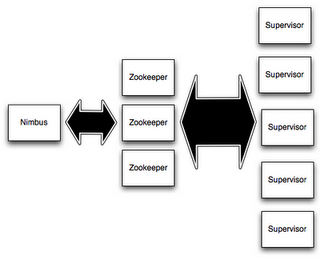
Il existe aussi une interface graphique pour administrer le cluster, ainsi qu’un client, pour soumettre et gérer les topologies..
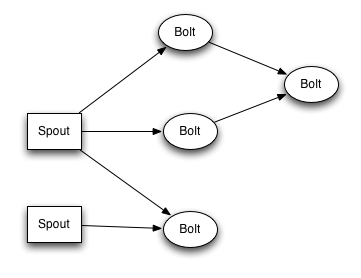
Les Topologies
Une topologie Storm définit un graphe de traitement sur un flux de données. Des tuples sont échangés entre des unités de calcul appelées spouts et bolts. Les spouts désignent des sources de données (ils fournissent des tuples), tandis que les bolts effectuent des calculs et des transformations.
Les topologies Storm sont packagées sous la forme de fichiers JAR (bien que d’autres langages que Java soient aussi supportés). Une fois empaquetée, une topologie peut être soumise au Nimbus, qui la répartira sur l’ensemble des nœuds workers.
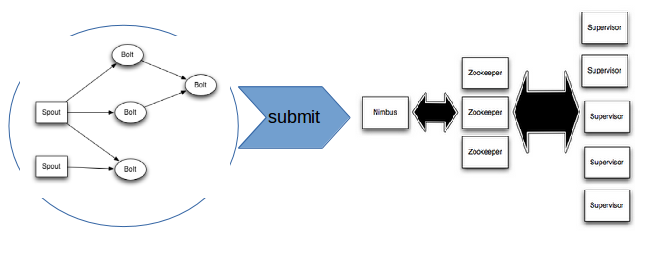
Storm permet de redistribuer une topologie quand le cluster évolue, ainsi qu’une reprise des calculs perdus dans le cas où un nœud tombe. Voir cette page pour plus de détails.
Déploiement Manuel avec Docker
Dans le cadre de cet exercice, vous allez d’abord déployer une topologie Storm à la main, via Docker.
Commençons par l’installation d’un Zoo Keeper.
docker run -d --restart always --name zookeeper zookeeper:3.3
Poursuivons par l’installation d’un Nimbus.
docker run -d --restart always --name nimbus --link zookeeper:zookeeper storm:1.1 storm nimbus
Puis créeons des nœuds de travail.
docker run -d --restart always --name supervisor1 --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
docker run -d --restart always --name supervisor2 --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
# ...
docker run -d --restart always --name supervisorN --link zookeeper:zookeeper --link nimbus:nimbus storm:1.1 storm supervisor
Nous pouvons également installer l’interface d’administration.
# Disponible à l'adresse : http://localhost:9090/index.html
docker run -d -p 9090:8080 --restart always --name ui --link nimbus:nimbus storm:1.1 storm ui
Notez les différentes relations entre les conteneurs.
Ces relations devront se retrouver dans le graphe Roboconf.
Reste à soumettre une topologie pour tester tout ça.
Parmi les exemples fournis par Storm, qui sont groupés ensemble, nous avons opté pour en extraire
un tout simple et très léger. Il est disponible sous la forme d’un projet source
à compiler avec Maven. Il s’agît d’une topologie très simple dans laquelle des mots sont générés aléatoirement
et pour lesquels on calcule leur longueur.
# JAR disponible sous le dossier "target"
mvn clean package
Vous pouvez ensuite gérer cette topologie via des conteneurs Docker éphémères.
# Aller dans le dossier "target"
cd target/
# Soumettre
docker run --link nimbus:nimbus -it --rm -v \
$(pwd)/storm-starter-word-count-1.1.0.jar:/topology.jar \
storm:1.1 storm jar /topology.jar org.apache.storm.starter.WordCountTopology <topology-name>
# Redistribuer sur le cluster
docker run --link nimbus:nimbus -it --rm storm:1.1 storm rebalance <topology-name>
# Supprimer
docker run --link nimbus:nimbus -it --rm storm:1.1 storm kill <topology-name>
Vérifiez ce qui se passe dans la console web de Storm.
Attention, l’arrêt ou la redistribution d’une topologie prennent un peu de temps.
Maintenant que vous êtes à l’aise avec Storm, essayons de le packager pour Roboconf.