Tutoriel - Apache Storm
Introduction
Apache Storm est généralement utilisé pour du calcul temps-réel sur de grandes volumétries de données (big data). On parle de calcul continu, traitant des données au fil de l’eau, et impliquant des sources potentiellement nombreuses et diverses.
Storm permet de lancer des topologies (qui sont des graphes de traitement) sur une grappe de serveurs Storm.
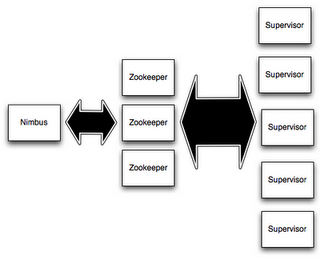
Une grappe Storm est composée de plusieurs nœuds, dont:
- Un nœud maître, appelé Nimbus.
- Des nœuds esclabes appelés supervisor nodes ou workers (plus exactement, les « workers » effectuent les calculs sur des nœuds « supervisor »).
- Des nœuds de coordination, qui s’appuient sur Apache Zookeeper.
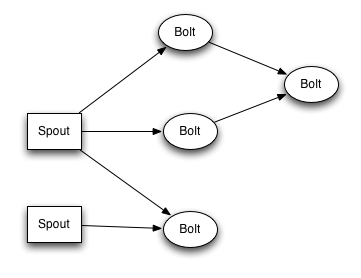
Une topologie Storm (graphe de traitement) définit le traitement du flux de données. Des tuples de données sont échangés entre chaque unité de traitement. Ces unités sont appelées “spouts” et “bolts”. Les “spouts” désignent des sources de données ; elles fournissent des tuples de données à traiter. Les “bolts” sont en charge de traitements tels que des transformations.
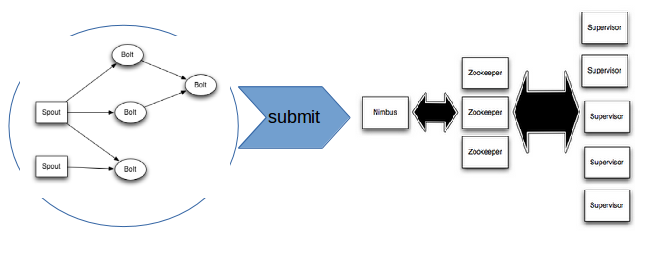
Les topologies Storm sont généralement embarquées dans un fichier JAR (d’autres langages que Java sont aussi supportés). Le fichier est ensuite soumis au nœud Nimbus (nœud maître de la grappe), qui va distribuer les unités de traitement (les spouts et les bolts) sur les nœuds de traitement.
Dans ce tutoriel, nous utilisons Roboconf pour déployer une grappe de serveurs Storm sur plusieurs machines virtuelles. Par commodité, nous allons utilisé Docker en lieu et place de machines virtuelles, mais le passage sur de véritables VMs est transparent, au fichier de configuration près.
Graphe Roboconf pour Storm
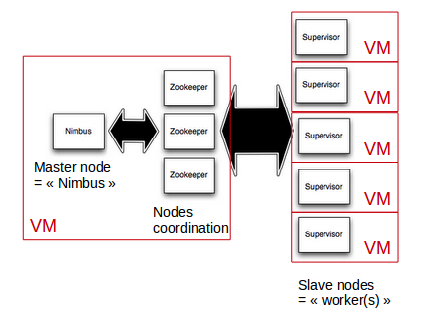
Pour faire simple, nous n’allons considérer que deux types de nœuds : le Nimbus (nœud maître) les nœuds de travail (Worker).
Le n&uds Nimbus embarquera une instance de ZooKeeper, ainsi que l’interface web d’administration de Storm.
L’ensemble formera une plate-forme Storm (chaque brique avec sa propre configuration). Les processus seront supervisés par supervisor.
A nœud de travail a besoin de connaître l’adresse IP du Nimbus. Il ne peut pas démarrer sans.
Il s’agît donc d’une dépendance d’exécution, au sens où Roboconf l’entend. Cette dépendance doit être résolue avant de lancer
tout nœud de travail.
Nous avons donc :
- Nimbus : Storm + Supervisord + ZooKeeper + StormUI
- Worker : Storm + Supervisord
- Chaque type de nœud a ses propres fichiers de configurations
- Il y a une relation de dépendance entre le Nimbus et les nœuds de travail (adresse IP du Nimbus).
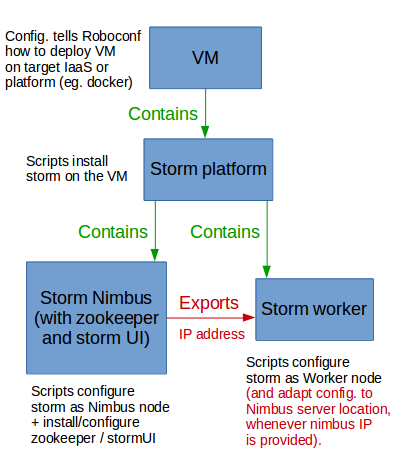
Dans le cadre de ce tutoriel, nous définissons donc le graphe suivant :
- storm_platform définit le processus de Storm (qui peut être lancé en mode nimbus ou en mode worker), ainsi que Supervisord.
- storm_worker se déploit sur une instance de storm_platform. Elle configure la plate-forme pour en faire un nœud de travail. Elle résoud l’adresse IP du Nimbus et l’injecte dans les fichiers de configuration.
- storm_nimbus se déploit sur une instance de storm_platform. Elle configure la partie Nimbus et rajoute les éléments additionnels, tels que ZooKepper et StormUI. Elle exporte également son adresse IP, dont dépendent les instances de storm_worker.
- VM désigne la machine sur laquelle tout cela se déploie. Ici, nous utilisons des conteneurs Docker comme substituts à des VMs, mais nous pourrions simplement basculer sur une véritable infrastructure virtualisée ou un cloud (via le fichier target.properties).
Ce qui se traduit par…
# La VM
VM {
installer: target;
children: storm_platform;
}
# La plate-forme de base pour Storm
storm_platform {
installer: script;
children: storm_nimbus, storm_worker;
}
# Nœuds Storm
# Nœud maître (Nimbus + ZooKeeper + StormUI)
storm_nimbus {
installer: script;
exports: ip;
}
# Nœud de travail
storm_worker {
installer: script;
imports: storm_nimbus.ip;
}
Préparer les fichiers
Les exemples Roboconf peuvent être écupérés sur Github.
git clone https://github.com/roboconf/roboconf-examples.git
Allez ensuite dans le répertoire roboconf-examples/storm-bash , vous y trouverez les ressources nécessaires.
Utilisez Maven pour la validation et l’assemblage:
mvn clean install
L’archive à charger dans Roboconf se trouve sous le dossier target/ (exemple : storm-bash-%v_SNAP%.zip).
Organisation du Projet
src/main/model
├── descriptor
│ └── application.properties
├── graph (relations entre composants logiciels avec recettes)
│ ├── graph.graph
│ ├── storm_platform
│ │ ├── files
│ │ └── scripts (gestion du cycle de vie)
│ │ ├── deploy.sh
│ │ ├── start.sh
│ │ ├── stop.sh
│ │ ├── undeploy.sh
│ │ └── update.sh
│ ├── storm_nimbus
│ │ ├── files (fichiers de configuration)
│ │ │ ├── nimbus.cfg
│ │ │ ├── storm.yaml
│ │ │ └── zoo.cfg
│ │ └── scripts (gestion du cycle de vie)
│ │ ├── deploy.sh
│ │ ├── start.sh
│ │ ├── stop.sh
│ │ ├── undeploy.sh
│ │ └── update.sh
│ ├── storm_worker
│ │ ├── files (fichiers de configuration)
│ │ │ ├── storm.yaml
│ │ │ └── worker.cfg
│ │ └── scripts (gestion du cycle de vie)
│ │ ├── deploy.sh
│ │ ├── start.sh
│ │ ├── stop.sh
│ │ ├── undeploy.sh
│ │ └── update.sh
│ └── VM
│ └── target.properties
└── instances (topologie initiale, conforme au graphe)
└── initial.instances
Prérequis
Installez le serveur de messagerie (RabbitMQ)
ainsi que la brique d’administration de Roboconf.
Si vous avez déjà suivi le tutoriel débuter avec Roboconf, alors vous avez déjà tout ce qu’il faut.
Docker est é&galement nécessaire, à moins que vous n’utilisiez une véritable infrastructure.
Concernant docker, vous pouvez vous référer à ces conseils.
Démarrez ensuite le DM and préparez-le pour interagir avec Docker.
Dans la console interactive du DM, tapez…
# Here in version %v_SNAP%
bundle:install mvn:net.roboconf/roboconf-target-docker/%v_SNAP%
bundle:start <bundle-id>
Vous pouvez ensuite vous rendre sur l’interface web de Roboconf.
http://localhost:8181/roboconf-web-administration/index.html
Déployer l’application avec Roboconf
- Chargez l’archive ZIP (celle qui était sous le dossier target) en tant que nouvelle application.
- Rendez-vous sur la page des instances, et jouez avec leur cycle de vie (déployer, démarrer, etc).
A partir de la version 0.9 de Roboconf, la cible Docker les images Docker officielles de Roboconf, basées sur le système Alpine. Il se peut que vous ayez à corriger les scripts qui gèrent le cycle de vie des briques logicielles.